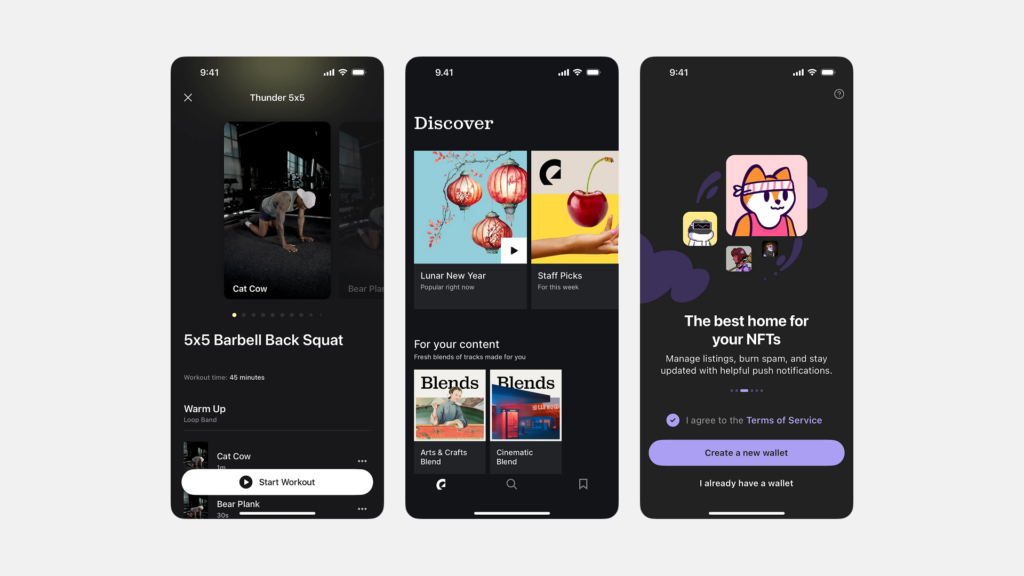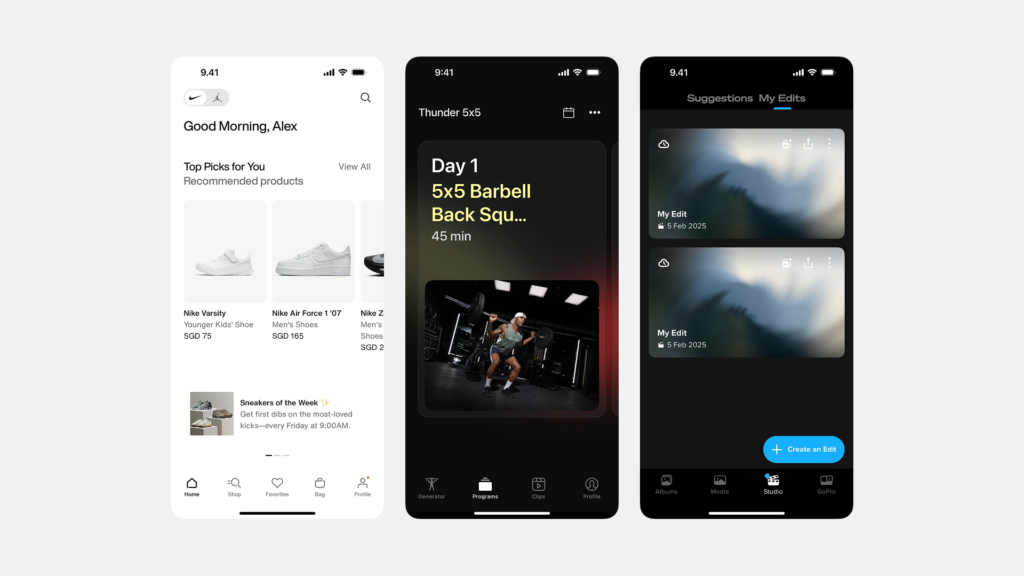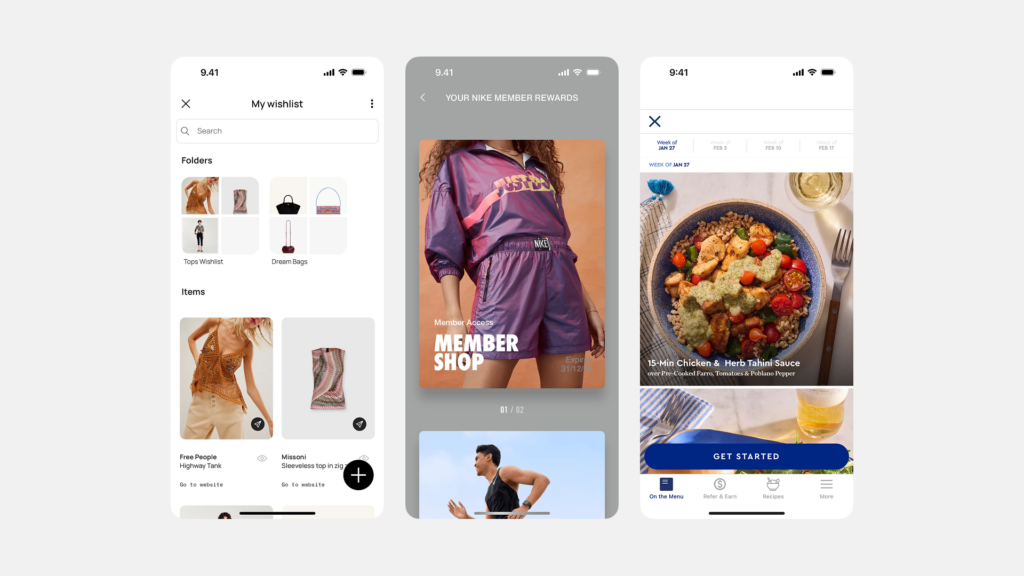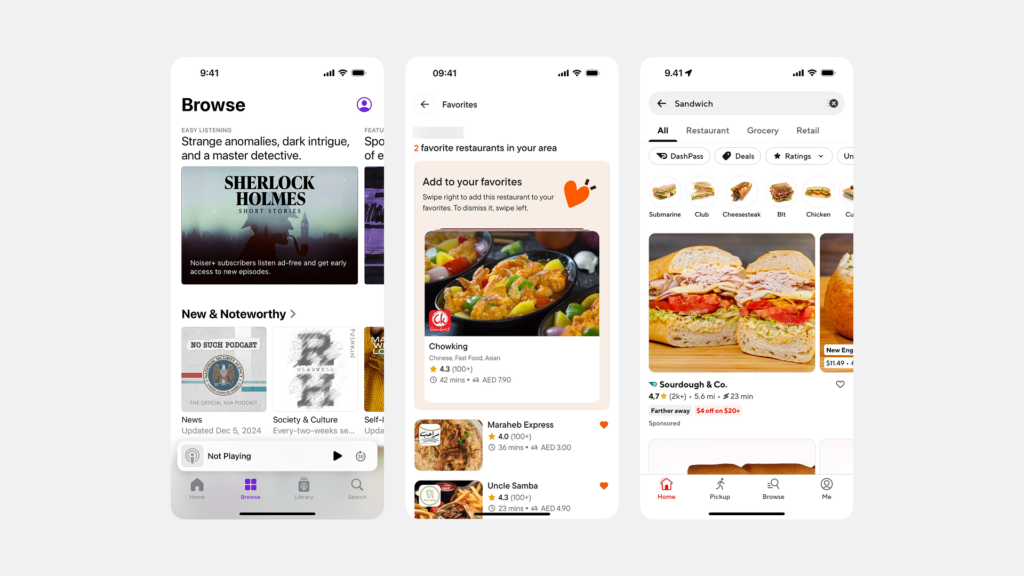
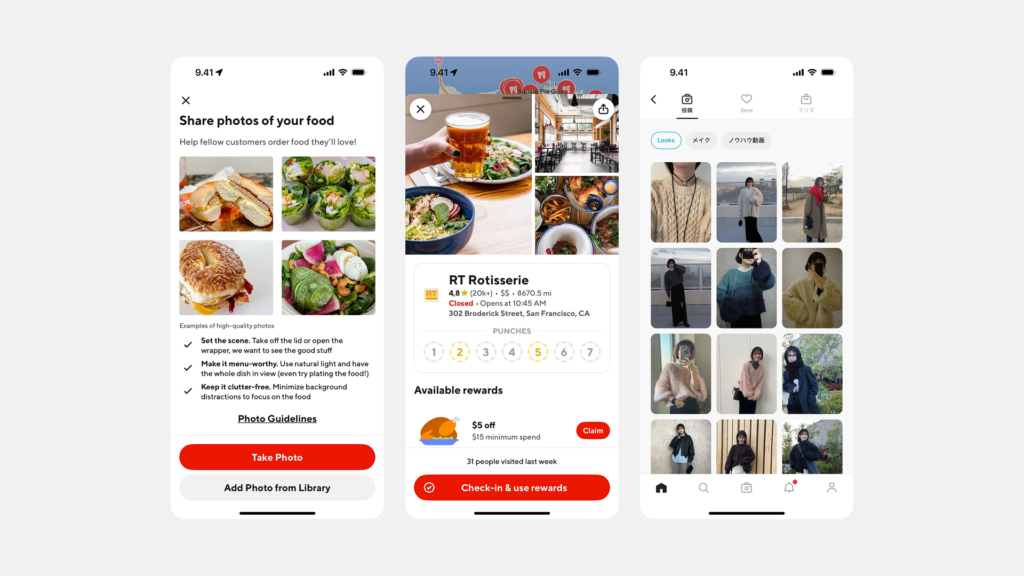
스크롤을 멈추게 하는 아름다움: 시선을 사로잡는 UI 갤러리 디자인의 비밀
“백문이 불여일견(百聞不如一見)”이라는 말처럼, 때로는 하나의 이미지가 천 마디 말보다 더 강력한 메시지를 전달합니다. 현대 디지털 환경은 이미지, 비디오 등 시각적 콘텐츠가 넘쳐나는 시대이며, 이러한 콘텐츠들을 사용자에게 얼마나 효과적이고 매력적으로 보여주느냐가 서비스 경험의 질을 결정하는 중요한 요소가 되었습니다. 바로 이 지점에서 UI ‘갤러리(Gallery)’ 패턴이 핵심적인 역할을 수행합니다. 갤러리는 여러 개의 시각적 콘텐츠(주로 이미지나 비디오 썸네일)를 한 곳에 모아 사용자가 컬렉션을 훑어보고 탐색하며 원하는 항목을 발견하고 더 자세히 살펴볼 수 있도록 구성하는 인터페이스 레이아웃 방식입니다. 마치 미술관에서 여러 작품을 둘러보듯, 잘 디자인된 갤러리는 콘텐츠 자체의 매력을 극대화하여 사용자의 시선을 사로잡고, 풍부한 시각적 탐색 경험을 제공하며, 때로는 사용자의 감성을 자극하여 깊은 인상을 남기기도 합니다. 이커머스 플랫폼의 화려한 상품 진열장부터, 디자이너의 영감이 담긴 포트폴리오, 소중한 추억이 담긴 개인 사진 앨범에 이르기까지, 갤러리는 시각 콘텐츠를 다루는 거의 모든 디지털 서비스에서 필수 불가결한 요소로 자리 잡았습니다. 따라서 제품 책임자(PO), UX/UI 디자이너, 개발자라면 사용자의 스크롤을 멈추게 만드는 매력적인 갤러리 디자인의 원리와 전략을 깊이 이해해야 합니다.
갤러리 UI란 무엇인가?: 핵심 개념 파헤치기
UI 갤러리(Gallery)는 주로 이미지나 비디오와 같은 다수의 시각적 콘텐츠 항목들을 모아서 특정 레이아웃(주로 그리드 형태)으로 배열하여 보여주는 사용자 인터페이스 영역 또는 패턴을 의미합니다. 사용자는 갤러리를 통해 전체 컬렉션을 한눈에 훑어보거나 스크롤하며 탐색하고, 그중 관심 있는 특정 항목(썸네일)을 선택하여 더 큰 크기로 보거나 관련 상세 정보 페이지로 이동하는 등의 상호작용을 하게 됩니다. 즉, 갤러리는 시각 콘텐츠의 ‘전시장’이자 ‘탐색의 시작점’ 역할을 수행하는 중요한 UI 구성 요소입니다.
갤러리의 주요 특징
갤러리 UI가 시각 콘텐츠를 보여주는 데 효과적인 이유는 다음과 같은 주요 특징들 때문입니다.
- 시각 중심성 (Visual-centric): 갤러리는 본질적으로 텍스트보다는 이미지, 비디오, 일러스트레이션 등 시각적 요소가 주인공이 되는 인터페이스입니다. 콘텐츠의 시각적인 매력을 최대한 활용하여 사용자의 흥미를 유발하고 정보를 전달합니다.
- 컬렉션 전시 (Collection Display): 여러 개의 관련 항목들을 한 곳에 모아 ‘컬렉션’ 형태로 보여줌으로써, 사용자가 전체적인 규모나 다양성을 파악하고 개별 항목들을 비교하며 탐색하기 용이하게 만듭니다.
- 탐색 및 발견 지원 (Browse & Discovery): 사용자가 정해진 순서 없이 자유롭게 갤러리를 훑어보면서(Browse) 자신의 취향에 맞는 콘텐츠를 발견(Discovery)하는 경험을 촉진합니다. 특히 영감을 얻거나 특별한 목적 없이 둘러보는 상황에서 효과적입니다.
- 점진적 정보 제공 (Progressive Disclosure via Thumbnails): 처음에는 작은 크기의 썸네일 이미지를 통해 콘텐츠의 맛보기만 보여주고, 사용자가 관심을 보이며 클릭(탭)했을 때 비로소 더 큰 이미지나 상세 정보를 보여주는 ‘점진적 정보 제공’ 방식을 따릅니다. 이는 사용자가 정보 과부하 없이 탐색에 집중하도록 돕습니다.
- 확대 보기 및 상세 정보 연결 (Zoom-in & Link to Detail): 갤러리의 각 썸네일은 일반적으로 더 큰 크기의 이미지(주로 ‘라이트박스(Lightbox)’라는 모달 창 형태)로 확대하여 볼 수 있는 기능을 제공하거나, 해당 콘텐츠와 관련된 상세 정보 페이지(예: 상품 상세 페이지, 프로젝트 설명 페이지)로 연결되는 링크 역할을 수행합니다.
주요 갤러리 레이아웃 패턴
갤러리 내의 썸네일들을 배열하는 방식은 매우 다양하며, 각 레이아웃 패턴은 서로 다른 시각적 인상과 사용성을 제공합니다. 대표적인 패턴들은 다음과 같습니다.
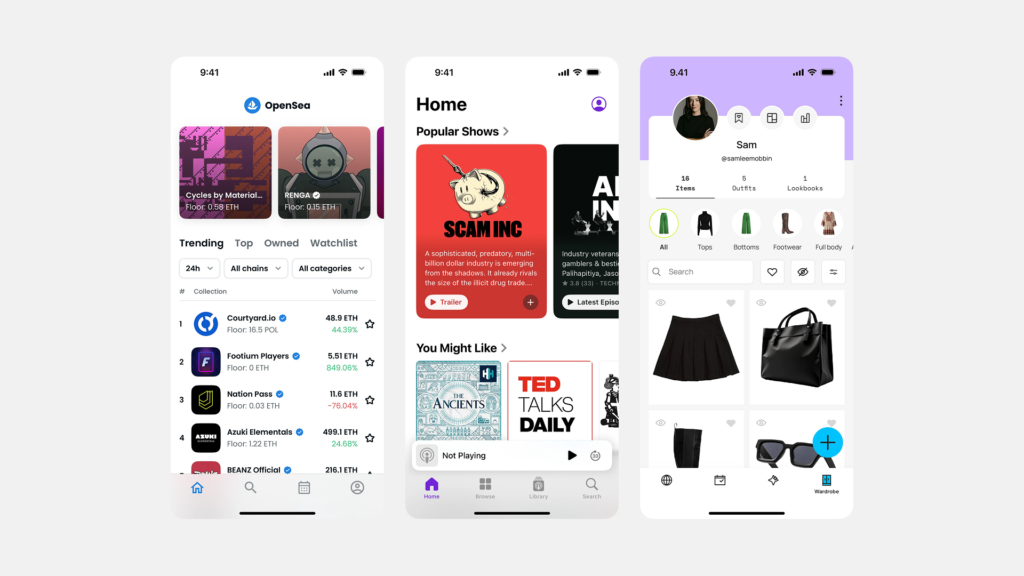
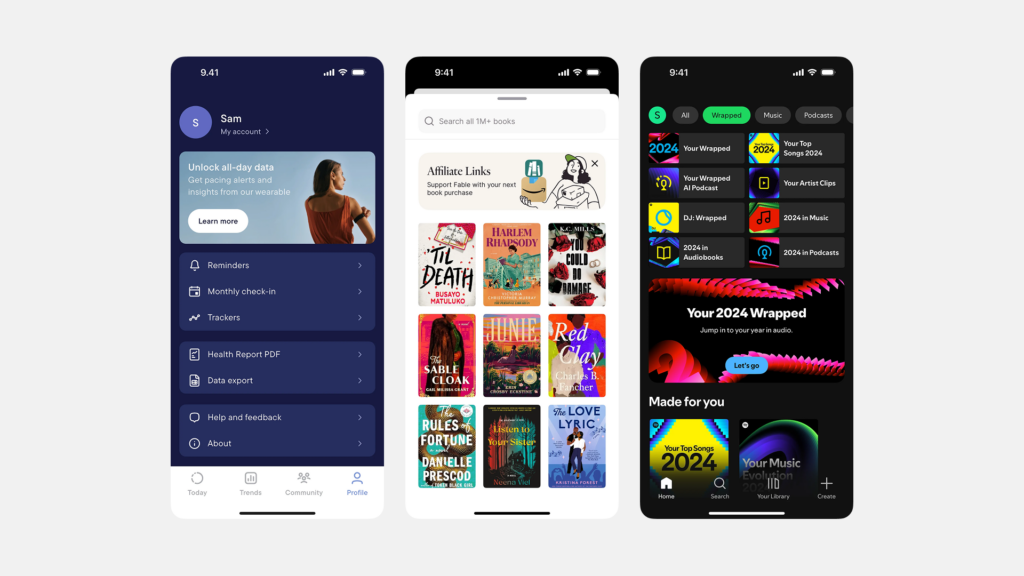
1. 균일 그리드 (Uniform Grid)
- 특징: 모든 썸네일 이미지(또는 썸네일을 담는 컨테이너)가 동일한 크기와 비율(주로 정사각형 또는 가로/세로 비율이 같은 직사각형)을 가지며, 행과 열이 명확한 격자무늬 형태로 배열됩니다. 가장 질서정연하고 예측 가능한 레이아웃입니다.
- 장점: 시각적으로 매우 안정적이고 깔끔하며, 사용자가 일정한 패턴으로 콘텐츠를 스캔하기 용이합니다. 구현이 비교적 간단합니다.
- 단점: 모든 이미지를 동일한 비율로 강제해야 하므로, 원본 이미지의 비율이 다양한 경우 이미지의 일부가 잘리거나(Cropped) 왜곡될 수 있습니다. 다소 단조롭게 느껴질 수도 있습니다.
- 주요 용례: 인스타그램 프로필 피드, 애플 앱스토어 스크린샷 목록, 이커머스 상품 목록 등.
2. 메이슨리 그리드 (Masonry Grid / Pinterest Layout)
- 특징: 갤러리 내 각 썸네일의 가로 폭(열 너비)은 동일하게 유지하되, 세로 길이는 원본 이미지의 비율에 따라 가변적으로 달라집니다. 마치 벽돌을 쌓듯이 높이가 다른 썸네일들을 수직적인 빈 공간 없이 효율적으로 채워나가는 방식으로 배열됩니다.
- 장점: 다양한 비율의 이미지를 원본 그대로 보여줄 수 있어 이미지 잘림 문제를 피할 수 있습니다. 시각적으로 매우 역동적이고 풍부한 느낌을 주며, 스크롤하며 탐색하는 재미를 더할 수 있습니다.
- 단점: 시각적인 질서가 균일 그리드보다 떨어져 보일 수 있으며, 사용자의 시선 이동 경로가 다소 복잡해질 수 있습니다. 구현 난이도가 상대적으로 높습니다.
- 주요 용례: 핀터레스트(Pinterest) 보드, 디자인 포트폴리오 사이트, 이미지 기반 블로그 레이아웃 등.
3. 저스티파이드 그리드 (Justified Grid / Justified Layout)
- 특징: 각 행(Row)의 전체 가로 폭을 이미지들로 빈틈없이 꽉 채우도록 썸네일의 크기와 가로세로 비율을 동적으로 조정하여 배열하는 방식입니다. 일반적으로 각 행의 높이는 동일하게 유지되거나 약간씩 달라질 수 있습니다.
- 장점: 화면 공간을 매우 효율적으로 사용하며, 갤러리 전체가 매우 깔끔하고 꽉 찬 느낌을 줍니다. 엣지 투 엣지(Edge-to-edge) 디자인에 잘 어울립니다.
- 단점: 원본 이미지의 비율이 강제로 조정되므로 일부 이미지에서 왜곡이 발생할 수 있습니다. 모든 행의 폭을 맞추기 위한 계산 로직이 필요하여 구현이 복잡할 수 있습니다.
- 주요 용례: Flickr, 500px 등 전문 사진 공유/판매 플랫폼, 스톡 이미지 사이트 등.
4. 캐러셀 / 슬라이더 갤러리 (Carousel / Slider Gallery)
- 특징: 여러 개의 이미지나 콘텐츠 슬라이드를 하나의 영역에서 순환하며 보여주는 방식입니다. 사용자는 이전/다음 버튼이나 페이지 표시기, 또는 스와이프 제스처를 통해 슬라이드를 넘겨봅니다. (이전 ‘캐러셀’ 컴포넌트 글에서 상세히 다룸)
- 장점: 제한된 공간에서 여러 이미지를 보여줄 수 있습니다. 특정 순서대로 이미지를 보여주고 싶을 때 유용합니다.
- 단점: 모든 이미지를 한눈에 보기 어렵고, 사용자가 모든 슬라이드를 탐색하지 않을 가능성이 높습니다. 사용성 측면에서 주의가 필요합니다.
- 주요 용례: 상품 상세 페이지의 여러 각도 이미지, 웹사이트 메인 히어로 섹션, 특정 테마의 이미지 그룹 소개 등.
5. 단일 열 / 리스트 갤러리 (Single Column / List Gallery)
- 특징: 이미지를 주로 세로 방향으로 하나씩 나열하며, 각 이미지 아래나 옆에 관련 텍스트 정보(제목, 설명, 날짜 등)를 함께 보여주는 방식입니다. 전통적인 블로그 포스트 목록이나 뉴스 기사 목록과 유사한 형태입니다.
- 장점: 각 이미지와 관련된 텍스트 정보를 함께 보여주기 용이하며, 세로 스크롤 환경에 자연스럽습니다.
- 단점: 한 화면에 보여줄 수 있는 이미지 개수가 적어 시각적 탐색 효율성은 그리드 방식보다 떨어질 수 있습니다.
- 주요 용례: 블로그, 뉴스 사이트, 튜토리얼 등 이미지와 텍스트 설명이 함께 중요한 경우.
어떤 갤러리 레이아웃을 선택해야 할까? (간단 비교)
| 레이아웃 패턴 | 주요 특징 | 장점 | 단점 | 적합한 콘텐츠/상황 |
| 균일 그리드 | 동일 크기/비율 썸네일, 격자 배열 | 질서정연, 예측 가능, 스캔 용이, 구현 용이 | 이미지 잘림/왜곡 가능성, 단조로울 수 있음 | 앱 아이콘 목록, 동일 비율 이미지 컬렉션, 인스타그램 피드 등 |
| 메이슨리 그리드 | 가변 높이 썸네일, 벽돌 쌓기 배열 | 다양한 비율 이미지 표현 용이, 역동적/풍부한 느낌, 공간 효율적 | 시선 분산 가능성, 구현 복잡성 | 핀터레스트 보드, 포트폴리오, 이미지 블로그 등 |
| 저스티파이드 그리드 | 행 폭 맞춤, 가변 크기/비율 썸네일 | 공간 효율성 극대화, 깔끔하고 꽉 찬 느낌 | 이미지 비율 왜곡 가능성, 구현 복잡성 | 전문 사진 갤러리, 스톡 이미지 사이트 등 |
| 캐러셀/슬라이더 | 순환 슬라이드, 네비게이션 컨트롤 필요 | 공간 효율성, 순차적 스토리텔링 가능 | 낮은 발견 가능성, 사용성 문제(자동 재생 등), 접근성 이슈 | 상품 상세 이미지, 히어로 배너, 온보딩 튜토리얼 등 |
| 단일 열/리스트 | 세로 나열, 이미지 + 텍스트 정보 결합 | 텍스트 정보 함께 보기 용이, 세로 스크롤 자연스러움 | 시각적 탐색 효율성 낮음, 한 화면 노출 개수 적음 | 블로그, 뉴스, 튜토리얼 등 설명이 함께 중요한 경우 |
최적의 레이아웃 선택은 보여주고자 하는 콘텐츠의 특성(이미지 비율의 다양성, 텍스트 정보의 중요도 등), 사용자의 주된 탐색 목표(빠른 스캔? 상세 비교? 영감 얻기?), 그리고 전체적인 디자인 콘셉트와 기술적 구현 가능성을 종합적으로 고려하여 결정해야 합니다.
갤러리는 언제, 어떻게 사용해야 할까?: 용처 및 모범 사례
갤러리 UI는 시각적 콘텐츠를 효과적으로 전시하고 사용자의 탐색 경험을 풍부하게 만드는 강력한 도구입니다. 하지만 그 잠재력을 최대한 발휘하기 위해서는 갤러리가 적합한 용처를 파악하고, 사용자 중심적인 디자인 모범 사례를 따르는 것이 중요합니다.
갤러리의 주요 용처
갤러리 UI 패턴은 다음과 같은 상황에서 시각 콘텐츠를 보여주는 데 매우 효과적입니다.
- 사진 및 비디오 앨범: 사용자가 개인적으로 촬영하거나 저장한 다수의 사진과 비디오를 모아보고 관리하는 데 가장 기본적인 방식으로 사용됩니다. 날짜별, 앨범별, 인물별 등 다양한 기준으로 정렬된 갤러리를 제공합니다.
- 예시: 스마트폰 기본 사진 앱 (구글 포토, 애플 사진), 클라우드 스토리지 서비스 (구글 드라이브, 드롭박스), 페이스북 사진첩 등.
- 포트폴리오 전시: 디자이너, 사진작가, 일러스트레이터, 건축가 등 시각적인 결과물이 중요한 전문가들이 자신의 작업물을 잠재 고객이나 고용주에게 보여주는 데 필수적입니다. 각 작품의 매력을 최대한 살릴 수 있는 갤러리 레이아웃(메이슨리, 균일 그리드 등)을 선택하는 것이 중요합니다.
- 예시: 비핸스(Behance), 드리블(Dribbble), 개인 포트폴리오 웹사이트 등.
- 이커머스 상품 목록: 온라인 쇼핑몰에서 다양한 상품들을 시각적으로 보여주고 사용자가 비교하며 탐색하도록 돕는 핵심적인 인터페이스입니다. 상품 이미지가 구매 결정에 큰 영향을 미치므로, 매력적인 썸네일과 깔끔한 갤러리 구성이 중요합니다.
- 예시: 거의 모든 온라인 쇼핑몰의 카테고리 페이지, 검색 결과 페이지, 관련 상품 추천 섹션 등.
- 소셜 미디어 콘텐츠 피드: 특히 이미지나 비디오 콘텐츠가 중심이 되는 소셜 미디어 서비스에서 사용자들이 공유한 콘텐츠를 보여주는 데 사용됩니다. (카드 UI와 결합된 형태가 많습니다.)
- 예시: 인스타그램 탐색 탭, 핀터레스트 홈 피드 등.
- 디자인 영감 및 스톡 이미지 플랫폼: 사용자들이 다양한 시각 자료를 탐색하고 영감을 얻거나 필요한 이미지를 찾는 것을 목적으로 하는 서비스에서 핵심적인 역할을 합니다. 방대한 양의 이미지를 효율적으로 보여주고 검색/필터링하는 기능이 중요합니다.
- 예시: 핀터레스트, 언스플래시(Unsplash), 게티이미지(Getty Images) 등.
- 뉴스 기사 내 멀티미디어 콘텐츠: 하나의 뉴스 기사 내에서 관련된 여러 장의 사진이나 비디오 클립을 모아서 보여줄 때 사용됩니다. 기사의 내용을 보충하고 독자의 이해를 돕는 역할을 합니다. (캐러셀 형태나 작은 그리드 형태)
- 테마 또는 배경화면 선택: 운영체제나 특정 앱에서 사용자가 적용할 수 있는 다양한 테마나 배경화면 이미지 옵션들을 시각적으로 미리 볼 수 있도록 갤러리 형태로 제공합니다.
이처럼 갤러리는 시각적 요소가 핵심이고, 여러 항목을 탐색하거나 비교해야 하며, 컬렉션 형태로 정보를 보여주는 것이 효과적인 거의 모든 상황에 적용될 수 있습니다.
성공적인 갤러리 디자인을 위한 모범 사례
사용자에게 매력적이고 효율적인 갤러리 경험을 제공하기 위해 다음과 같은 디자인 원칙과 모범 사례들을 고려해야 합니다.
1. 고품질의 매력적인 썸네일은 기본 중의 기본
갤러리의 성패는 썸네일 이미지의 품질에 달려있다고 해도 과언이 아닙니다. 썸네일은 사용자가 콘텐츠를 클릭할지 말지를 결정하는 첫인상입니다. 따라서 이미지는 선명하고, 내용이 잘 드러나며, 시각적으로 매력적이어야 합니다. 저해상도거나 내용과 무관한 썸네일은 사용자 경험을 크게 저해합니다.
2. 레이아웃에 맞는 일관된 썸네일 스타일 유지
선택한 갤러리 레이아웃 패턴에 맞춰 썸네일의 스타일(크기, 비율 등)을 일관되게 유지하는 것이 중요합니다. 예를 들어, 균일 그리드를 사용한다면 모든 썸네일의 크기와 비율을 통일하여 시각적 안정감을 주어야 합니다. (단, 이때 원본 이미지의 중요한 부분이 잘리지 않도록 주의하거나, 잘림(Crop)보다는 레터박스(Letterbox: 비율 유지를 위해 빈 공간 추가) 방식을 고려할 수도 있습니다.) 메이슨리 그리드라면 가로 폭은 통일하되 세로 길이는 다양하게 허용하여 역동성을 살립니다.
3. 적절한 간격(Gutter)으로 숨 쉴 공간 확보
썸네일과 썸네일 사이에는 적절한 여백(Gutter 또는 Spacing)을 두어야 합니다. 이 간격은 각 썸네일 이미지를 시각적으로 명확하게 분리하고, 전체적인 레이아웃이 답답해 보이지 않도록 숨 쉴 공간을 제공하며, 사용자가 개별 항목을 인지하고 선택하는 것을 돕습니다. 간격의 크기는 전체적인 디자인 톤앤매너와 썸네일 크기를 고려하여 일관되게 적용해야 합니다.
4. 명확하고 즉각적인 상호작용 피드백 제공
사용자는 어떤 썸네일이 상호작용 가능하며(클릭 가능), 클릭했을 때 어떤 일이 일어날지 명확하게 인지할 수 있어야 합니다.
- 호버(Hover) 효과: 데스크톱 환경에서 마우스 커서를 썸네일 위에 올렸을 때, 약간 확대되거나, 테두리가 생기거나, 반투명한 오버레이와 함께 아이콘(확대, 링크 등)이나 추가 정보가 나타나는 등의 시각적 피드백을 제공하여 상호작용 가능성을 알려줍니다.
- 클릭(탭) 피드백: 썸네일을 클릭(탭)했을 때, 로딩 중임을 나타내는 표시(스피너 등)나, 이미지가 확대되는 애니메이션 효과, 또는 라이트박스가 부드럽게 나타나는 전환 효과 등을 제공하여 사용자가 자신의 행동에 대한 시스템의 반응을 즉시 인지하도록 합니다.
5. 효과적인 라이트박스(Lightbox) 또는 상세 보기 경험 설계
썸네일을 클릭했을 때 이미지를 더 크게 보여주는 라이트박스(화면 위에 떠오르는 모달 창 형태)는 사용자가 현재 페이지를 벗어나지 않고도 콘텐츠를 자세히 살펴볼 수 있게 하는 매우 유용한 패턴입니다. 좋은 라이트박스 경험을 위해서는 다음 요소들을 고려해야 합니다.
- 쉬운 탐색: 라이트박스 내에서 이전/다음 이미지로 쉽게 이동할 수 있는 버튼이나 스와이프 제스처를 제공합니다.
- 명확한 닫기: 라이트박스를 쉽게 닫을 수 있는 ‘X’ 버튼을 눈에 잘 띄는 곳에 배치하거나, 배경 영역을 클릭해도 닫히도록 구현합니다.
- 부가 정보 제공 (선택 사항): 이미지 제목, 설명, 촬영 정보(EXIF), 작성자, 좋아요/댓글 수 등의 관련 정보를 라이트박스 내에 함께 표시할 수 있습니다.
- 추가 액션 제공 (선택 사항): 이미지 다운로드, 공유하기, 원본 보기, 댓글 달기 등의 추가적인 액션 버튼을 제공할 수 있습니다.
- 키보드 제어 및 접근성: 키보드(좌우 화살표 키, Esc 키 등)만으로도 라이트박스 내 탐색 및 닫기가 가능해야 하며, 스크린 리더 사용자에게도 이미지 정보와 컨트롤 기능이 명확하게 전달되어야 합니다. 포커스 관리(라이트박스가 열렸을 때 포커스를 내부로 이동시키고, 닫혔을 때 원래 위치로 복귀)가 매우 중요합니다.
6. 성능 최적화, 특히 이미지 로딩 속도에 집중
갤러리는 본질적으로 많은 이미지를 동시에 로드해야 하는 경우가 많아 웹사이트나 앱의 성능(특히 로딩 속도)에 큰 영향을 미칠 수 있습니다. 느린 로딩 속도는 사용자 이탈의 주요 원인이므로 성능 최적화는 필수입니다.
- 이미지 파일 최적화: 웹에 적합한 포맷(JPEG, PNG, WebP, AVIF 등)을 사용하고, 이미지 품질을 크게 손상시키지 않는 선에서 파일 크기를 최대한 압축합니다.
- 반응형 이미지: 다양한 화면 크기에 맞는 여러 해상도의 이미지를 준비하고, 사용자의 기기 환경에 최적화된 크기의 이미지만 로드하도록 구현합니다 (
srcset,<picture>태그 활용). - 썸네일 크기 최적화: 갤러리에 표시되는 썸네일 이미지 자체의 크기(가로x세로 픽셀)를 실제 표시되는 크기에 맞게 미리 생성하여 불필요하게 큰 원본 이미지를 로드하지 않도록 합니다.
- 지연 로딩 (Lazy Loading): 사용자가 스크롤하여 화면에 실제로 보이는 영역(Viewport)에 들어왔을 때만 해당 이미지를 로드하는 기술입니다. 초기 페이지 로딩 속도를 크게 개선할 수 있습니다.
- 점진적 로딩 (Progressive Loading): 이미지를 처음에는 낮은 해상도나 흐릿한 형태로 빠르게 보여주고, 점차적으로 선명한 고해상도 이미지로 로드하는 방식입니다. 사용자가 빈 화면을 보는 시간을 줄여줍니다.
7. 반응형 디자인은 타협 불가
갤러리는 데스크톱의 넓은 화면부터 모바일의 작은 화면까지 모든 기기에서 최적의 모습으로 보여야 합니다. 화면 너비에 따라 그리드의 열 개수를 동적으로 변경하거나, 썸네일의 크기를 조절하거나, 모바일에서는 단일 열 레이아웃으로 전환하는 등 유연한 반응형 디자인을 반드시 구현해야 합니다.
8. 정렬 및 필터링 기능으로 탐색 지원 (선택 사항)
갤러리에 표시되는 콘텐츠의 양이 매우 많을 경우, 사용자가 원하는 항목을 효율적으로 찾거나 탐색 범위를 좁힐 수 있도록 도와주는 정렬(예: 최신순, 인기순, 가격순) 및 필터링(예: 카테고리, 색상, 태그, 날짜 범위) 기능을 제공하는 것을 고려해야 합니다. 이는 특히 이커머스나 스톡 이미지 사이트 등에서 매우 중요합니다.
9. 웹 접근성 준수는 기본 윤리
모든 사용자가 갤러리의 시각 콘텐츠에 동등하게 접근하고 이해할 수 있도록 웹 접근성 지침(WCAG)을 준수하는 것은 기본적인 책임입니다.
- 의미 있는 대체 텍스트: 모든 썸네일 이미지에는 해당 이미지의 내용을 설명하는 구체적이고 의미 있는 대체 텍스트(
alt속성)를 제공해야 합니다. “이미지 1″과 같은 무의미한 텍스트는 피해야 합니다. - 키보드 네비게이션: 키보드 사용자(Tab, Shift+Tab, 화살표 키 등)가 갤러리 내의 모든 썸네일을 순차적으로 탐색하고, 원하는 썸네일을 선택(Enter 또는 Space)하여 라이트박스를 열거나 상세 페이지로 이동할 수 있어야 합니다. 현재 포커스를 받은 썸네일은 명확하게 시각적으로 표시되어야 합니다.
- 라이트박스 접근성: 라이트박스가 열렸을 때 키보드 포커스가 라이트박스 내부로 이동하고 그 안에서만 머물도록(Focus Trap) 구현하며, Esc 키로 닫을 수 있어야 합니다. 라이트박스 내의 이미지 정보와 컨트롤 요소들도 스크린 리더와 키보드로 접근 가능해야 합니다.
이러한 모범 사례들을 충실히 따르면, 사용자는 시각적으로 매력적일 뿐만 아니라 사용하기 편리하고 효율적인 갤러리 경험을 통해 원하는 콘텐츠를 즐겁게 탐색하고 발견할 수 있을 것입니다.
최신 트렌드 및 실제 적용 사례: 갤러리의 진화와 스마트한 활용
갤러리 UI는 단순히 이미지를 나열하는 것을 넘어, 사용자 경험을 더욱 풍부하고 몰입감 있게 만들기 위해 끊임없이 새로운 기술과 디자인 트렌드를 받아들이며 진화하고 있습니다. 이러한 최신 동향을 살펴보고 실제 서비스에서 어떻게 구현되고 있는지 분석하는 것은 더 나은 갤러리 디자인을 위한 중요한 영감을 제공합니다.
최신 갤러리 디자인 트렌드
- 몰입형(Immersive) 경험 강화: 사용자가 시각 콘텐츠 자체에 온전히 집중할 수 있도록 하는 디자인이 강조되고 있습니다. 썸네일 클릭 시 나타나는 라이트박스나 상세 보기 화면에서 주변의 불필요한 UI 요소들을 최소화하거나 숨기고(예: 전체 화면 모드 제공), 배경을 어둡게 처리하여 콘텐츠를 더욱 돋보이게 만드는 방식이 많이 사용됩니다. 360도 이미지나 VR 콘텐츠를 보여주는 갤러리도 등장하고 있습니다.
- 풍부해진 호버(Hover) 인터랙션: 데스크톱 환경에서 마우스 커서를 썸네일 위에 올렸을 때 단순한 시각적 변화를 넘어 더 많은 정보나 기능을 제공하는 인터랙션이 정교해지고 있습니다. 예를 들어, 이미지 위에 반투명한 오버레이와 함께 작성자 정보, 좋아요/조회수, 저장/공유 버튼 등이 부드러운 애니메이션 효과와 함께 나타나는 방식은 사용자 참여를 유도하고 추가적인 탐색 없이 빠른 액션을 가능하게 합니다.
- AI 기반의 지능형 갤러리: 인공지능(AI) 기술, 특히 컴퓨터 비전 기술의 발전은 갤러리 경험을 혁신하고 있습니다.
- 자동 분류 및 태깅: 사용자가 업로드한 수많은 사진들을 AI가 자동으로 분석하여 인물, 사물, 장소, 이벤트 등을 인식하고 관련 태그를 생성하거나 앨범으로 분류해줍니다. (예: 구글 포토)
- 스마트 검색: “작년 여름 바닷가에서 찍은 우리 가족사진”과 같이 자연어로 이미지를 검색할 수 있게 됩니다.
- 개인화된 큐레이션: 사용자의 선호도나 과거 상호작용 기록을 학습하여 개인에게 가장 관련성 높거나 흥미로울 만한 이미지를 갤러리 상단에 우선적으로 보여주는 등 개인화된 경험을 제공합니다.
- 다양하고 실험적인 그리드 레이아웃: 전통적인 균일 그리드에서 벗어나, 메이슨리, 저스티파이드 그리드는 물론, 크기가 다른 썸네일들을 의도적으로 불규칙하게 혼합하거나, 특정 썸네일을 강조하여 시각적 계층 구조를 만드는 등 더욱 다이나믹하고 실험적인 그리드 레이아웃을 시도하는 경향이 있습니다. 이는 시각적인 단조로움을 피하고 갤러리에 개성을 부여하는 데 도움을 줄 수 있습니다.
- 모바일 제스처의 적극적인 활용: 모바일 환경에서는 터치스크린의 장점을 살린 제스처 기반 인터랙션이 더욱 중요해지고 있습니다. 좌우 스와이프를 통한 캐러셀 갤러리 탐색은 기본이며, 핀치 투 줌(Pinch-to-zoom) 제스처를 사용하여 썸네일이나 라이트박스 이미지를 사용자가 원하는 만큼 확대/축소하여 볼 수 있는 기능 등이 보편화되고 있습니다.
- 성능 최적화 기술의 발전: WebP, AVIF와 같은 차세대 이미지 포맷의 등장, 더욱 정교해진 지연 로딩(Lazy Loading) 및 점진적 로딩(Progressive Loading) 기법, CDN(Content Delivery Network) 활용 등을 통해 많은 이미지를 포함하는 갤러리의 로딩 속도를 개선하려는 기술적인 노력이 계속되고 있습니다.
실제 앱/서비스 적용 사례 분석
다양한 분야의 대표적인 서비스들이 갤러리 UI를 어떻게 핵심적인 사용자 경험 요소로 활용하고 있는지 구체적인 사례를 통해 살펴보겠습니다.
- Instagram / Pinterest: 모바일 네이티브 앱 환경에서 갤러리 UI의 성공을 이끈 대표적인 서비스입니다. 인스타그램은 주로 정사각형의 균일 그리드를 사용하여 사용자의 프로필 피드를 깔끔하게 보여주고, 탐색 탭에서는 사용자의 관심사 기반 콘텐츠를 무한 스크롤 그리드 갤러리로 제공합니다. 핀터레스트는 다양한 세로 길이의 이미지를 효율적으로 보여주는 메이슨리 그리드를 통해 사용자의 시각적 탐색과 발견의 즐거움을 극대화합니다.
- Google Photos / Apple Photos: 사용자의 방대한 사진 라이브러리를 관리하고 탐색하는 데 최적화된 갤러리 인터페이스를 제공합니다. 주로 시간 순서 기반의 깔끔한 균일 그리드 레이아웃을 사용하며, AI 기술을 활용한 자동 분류(인물, 장소, 사물), 스마트 검색, 추억 만들기 등의 지능형 기능을 통해 단순한 이미지 저장을 넘어 개인의 추억을 관리하는 경험을 제공합니다.
- Unsplash / Pexels 등 스톡 이미지 플랫폼: 고품질의 사진 자체를 매력적으로 보여주는 것이 매우 중요하므로, 이미지 잘림을 최소화하고 화면을 꽉 채우는 듯한 느낌을 주는 저스티파이드(Justified) 그리드나 메이슨리(Masonry) 그리드 레이아웃을 선호하는 경향이 있습니다. 이미지 위에 마우스를 올리면 작가 정보, 해상도 정보, 다운로드 또는 컬렉션 추가 버튼 등이 나타나는 인터랙션을 제공합니다.
- 이커머스 플랫폼 (Amazon, SSG.COM, 오늘의집 등): 상품 목록을 효과적으로 보여주기 위해 대부분 균일 그리드 기반의 갤러리(카드 UI와 결합된 형태)를 사용합니다. 각 썸네일(카드)에는 상품 이미지 외에도 가격, 할인율, 평점, 사용자 리뷰 수, 배송 정보 등 구매 결정에 영향을 미치는 주요 정보들을 함께 표시하며, 필터링 및 정렬 기능과 긴밀하게 연동됩니다. ‘오늘의집’과 같이 사용자들이 올린 인테리어 사진을 보여주는 커뮤니티 기능에서는 메이슨리 그리드를 활용하기도 합니다.
- 포트폴리오 플랫폼 (Behance, Dribbble 등): 디자이너와 아티스트들이 자신의 작업물을 가장 효과적으로 전시할 수 있도록 다양한 갤러리 레이아웃 옵션을 제공합니다. 사용자는 주로 그리드 형태의 갤러리를 통해 여러 작업물의 썸네일을 훑어보고, 관심 있는 작품을 클릭하여 상세 내용을 확인합니다. 각 썸네일에는 작품의 ‘좋아요’ 수나 조회수 등이 함께 표시되어 인기도를 가늠할 수 있게 합니다.
데이터 기반 갤러리 디자인 최적화
갤러리 디자인의 효과는 사용자 행동 데이터 분석과 실험을 통해 객관적으로 평가하고 지속적으로 개선해야 합니다. 제품 책임자(PO), 데이터 분석가, UX 디자이너는 다음과 같은 접근 방식을 활용할 수 있습니다.
- 레이아웃별 사용자 행동 비교: 동일한 콘텐츠를 다른 갤러리 레이아웃(예: 균일 그리드 vs. 메이슨리 그리드)으로 보여주는 A/B 테스트를 수행하여, 각 레이아웃이 사용자의 스크롤 깊이, 특정 이미지 클릭률(CTR), 페이지 체류 시간, 최종 전환율(예: 상품 구매) 등에 미치는 영향을 비교 분석합니다.
- 썸네일 크기 및 정보 구성 최적화: 썸네일의 크기를 다르게 하거나, 썸네일 위에 표시되는 부가 정보(예: 가격 표시 유무, 좋아요 수 표시 위치)를 변경했을 때 사용자의 클릭 행동이나 정보 인지도가 어떻게 달라지는지 A/B 테스트를 통해 검증합니다.
- 이미지 로딩 속도와 사용자 이탈률 관계 분석: 이미지 최적화 기법(압축률 변경, 지연 로딩 적용 등)을 변경했을 때, 페이지 로딩 속도 변화와 사용자 이탈률 간의 상관관계를 분석하여 최적의 성능 목표를 설정합니다.
- 필터링/정렬 기능 사용 패턴 분석: 사용자들이 어떤 필터나 정렬 옵션을 가장 많이 사용하는지, 특정 필터 조합이 얼마나 효과적으로 사용자의 목표 달성을 돕는지 등을 분석하여 기능의 우선순위를 조정하거나 개선 방향을 도출합니다.
- 라이트박스 사용성 분석: 사용자들이 라이트박스 내에서 이미지를 얼마나 확대해서 보는지, 이전/다음 버튼을 얼마나 자주 사용하는지, 어떤 추가 정보나 액션 버튼을 많이 이용하는지 등을 분석하여 라이트박스 UI/UX를 개선합니다.
- 사용자 조사 및 피드백: 실제 사용자가 갤러리 인터페이스를 사용하는 모습을 관찰하고 인터뷰하여, 특정 레이아웃에 대한 선호도, 정보 탐색 과정에서의 어려움이나 불편함, 개선 제안 등 정성적인 피드백을 수집합니다.
데이터와 사용자 피드백에 기반한 반복적인 개선 과정을 통해 갤러리는 더욱 효과적이고 만족스러운 사용자 경험을 제공하는 방향으로 발전할 수 있습니다.
결론: 시각적 스토리텔링의 무대, 갤러리의 현명한 설계가 중요하다
UI 갤러리는 단순한 이미지 나열을 넘어, 시각적 콘텐츠가 가진 힘을 최대한 발휘하여 사용자의 시선을 사로잡고, 풍부한 정보를 전달하며, 즐거운 탐색과 발견의 경험을 선사하는 핵심적인 인터페이스 패턴입니다. 마치 잘 큐레이션된 전시 공간처럼, 효과적인 갤러리 디자인은 콘텐츠의 매력을 배가시키고 사용자의 몰입도를 높여 서비스의 가치를 향상시키는 데 결정적인 역할을 합니다. 사용자의 스크롤을 멈추게 하고 “더 보고 싶다”는 감정을 불러일으키는 잘 만들어진 갤러리는 그 자체로 강력한 경쟁력이 될 수 있습니다.
갤러리 UI 적용 시 반드시 고려해야 할 주의점
이처럼 중요하고 매력적인 갤러리 UI를 성공적으로 구현하고 사용자에게 최상의 경험을 제공하기 위해서는, 다음과 같은 핵심 원칙과 주의사항들을 반드시 신중하게 고려해야 합니다.
- 콘텐츠 품질이 모든 것의 시작이다 (Content is King, Still): 아무리 훌륭한 갤러리 디자인이라도 그 안에 담기는 콘텐츠(이미지, 비디오 등)의 품질이 낮거나 매력적이지 않다면 아무 소용이 없습니다. 선명하고, 고품질이며, 전달하고자 하는 메시지와 관련성이 높은 시각 콘텐츠를 확보하는 것이 모든 것의 시작입니다.
- 성능 최적화는 타협할 수 없는 필수 과제 (Performance is Non-negotiable): 특히 이미지가 많은 갤러리는 웹사이트나 앱의 성능, 특히 로딩 속도에 치명적인 영향을 미칠 수 있습니다. 사용자는 기다려주지 않습니다. 이미지 파일 최적화, 반응형 이미지 제공, 썸네일 크기 최적화, 지연 로딩(Lazy Loading) 등 성능 최적화 기술을 반드시 적용하여 빠르고 쾌적한 경험을 보장해야 합니다.
- 맥락에 맞는 최적의 레이아웃을 선택하라 (Choose the Right Layout for Context): 보여주고자 하는 콘텐츠의 특성(이미지 비율의 다양성, 텍스트 정보의 필요성 등)과 사용자의 주된 탐색 목표(빠른 스캔? 상세 비교? 시각적 영감 얻기?)를 면밀히 분석하여 가장 적합한 갤러리 레이아웃 패턴(균일 그리드, 메이슨리, 저스티파이드 등)을 신중하게 선택해야 합니다. ‘만능’ 레이아웃은 없습니다.
- 정보 과부하와 시각적 피로를 경계하라 (Avoid Information Overload & Visual Fatigue): 한 화면에 너무 많은 썸네일을 무작정 때려 넣는 것은 사용자를 압도하고 오히려 탐색을 방해할 수 있습니다. 적절한 썸네일 개수, 충분한 여백, 명확한 시각적 계층 구조를 통해 사용자가 편안하게 정보를 처리할 수 있도록 배려해야 합니다. 필요하다면 페이지네이션(Pagination)이나 ‘더보기(Load More)’ 버튼 등을 사용하여 콘텐츠 로딩을 분산시키는 것을 고려해야 합니다.
- 상호작용은 명확하고 직관적으로 설계하라 (Design Clear & Intuitive Interactions): 사용자는 썸네일을 보고 쉽게 클릭(탭)할 수 있어야 하며, 클릭 후에 어떤 일이 일어날지(이미지 확대? 페이지 이동?) 명확하게 예측할 수 있어야 합니다. 호버 효과, 로딩 상태 표시, 라이트박스 전환 애니메이션 등 상호작용 전반에 걸쳐 명확하고 부드러운 피드백을 제공하여 사용자의 혼란을 줄여야 합니다.
- 모든 사용자를 위한 접근성을 보장하라 (Ensure Accessibility for All Users): 갤러리는 시각적인 요소가 중심이지만, 시각 장애인을 포함한 모든 사용자가 콘텐츠 정보에 접근하고 인터페이스를 탐색할 수 있도록 설계되어야 합니다. 의미 있는 대체 텍스트 제공, 키보드 네비게이션 완벽 지원, 스크린 리더 호환성 확보, 라이트박스 등 동적 요소의 접근성 준수는 이제 선택이 아닌 기본적인 책임입니다.
결론적으로, UI 갤러리는 단순한 이미지 목록이 아니라, 시각적 스토리텔링을 통해 사용자와 소통하고 서비스의 가치를 전달하는 중요한 무대입니다. 제품 책임자, 디자이너, 개발자는 이 무대를 어떻게 구성하고 연출할 것인지 깊이 고민해야 합니다. 콘텐츠의 본질을 이해하고, 사용자 중심적인 관점에서 최적의 레이아웃과 인터랙션을 설계하며, 기술적인 완성도(성능, 접근성)를 확보하려는 노력이 뒷받침될 때, 비로소 갤러리는 사용자의 시선을 사로잡는 것을 넘어 마음까지 움직이는 강력한 힘을 발휘하게 될 것입니다.
#UI #UX #갤러리 #Gallery #이미지그리드 #레이아웃 #컴포넌트 #디자인 #사용자경험 #인터페이스 #웹디자인 #앱디자인 #시각디자인 #포트폴리오 #사용성