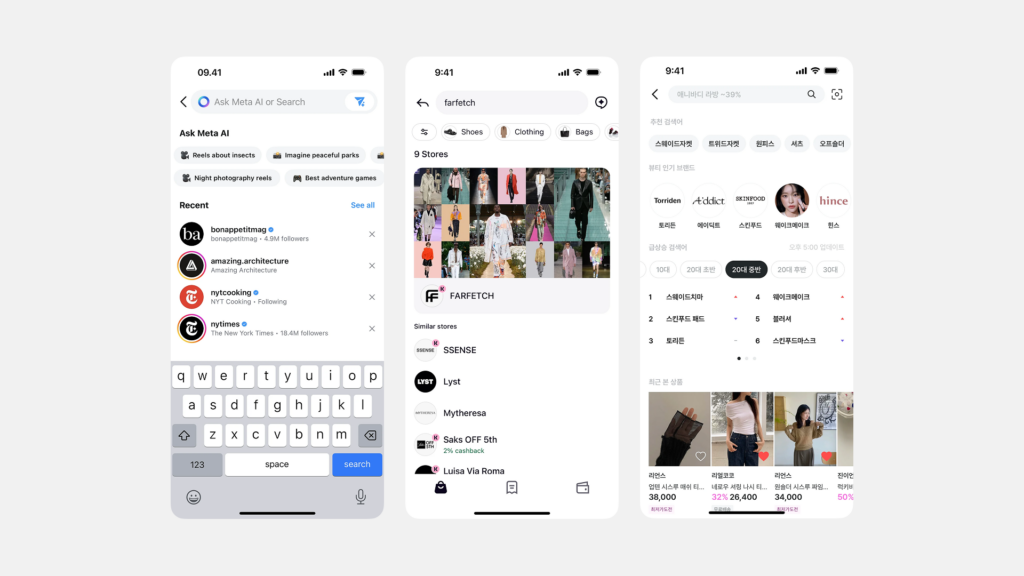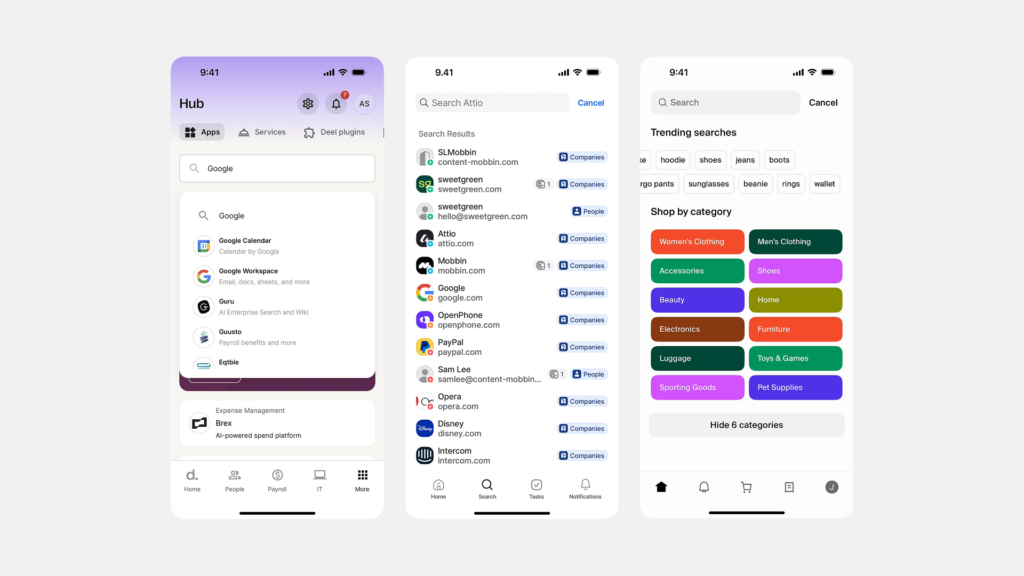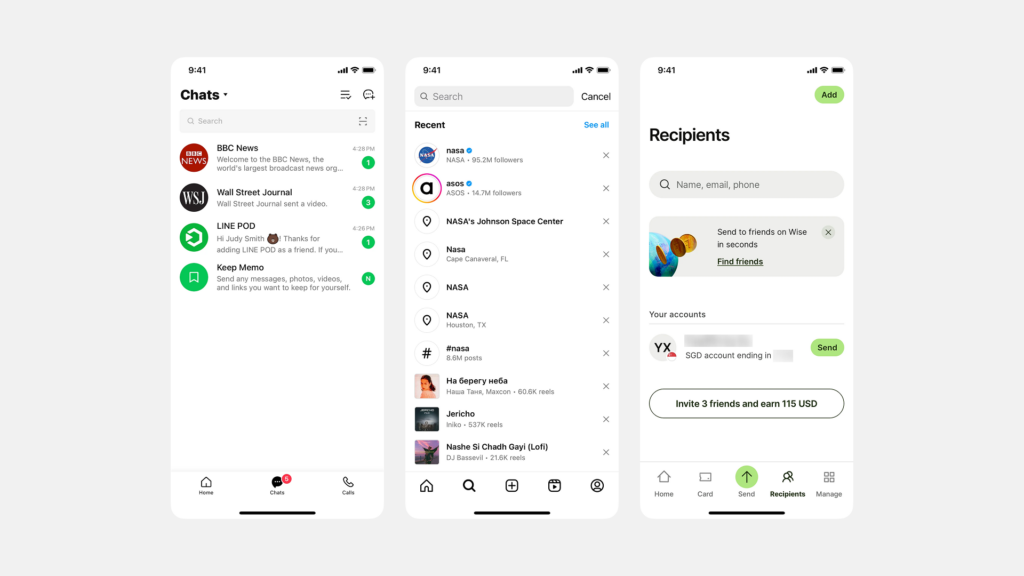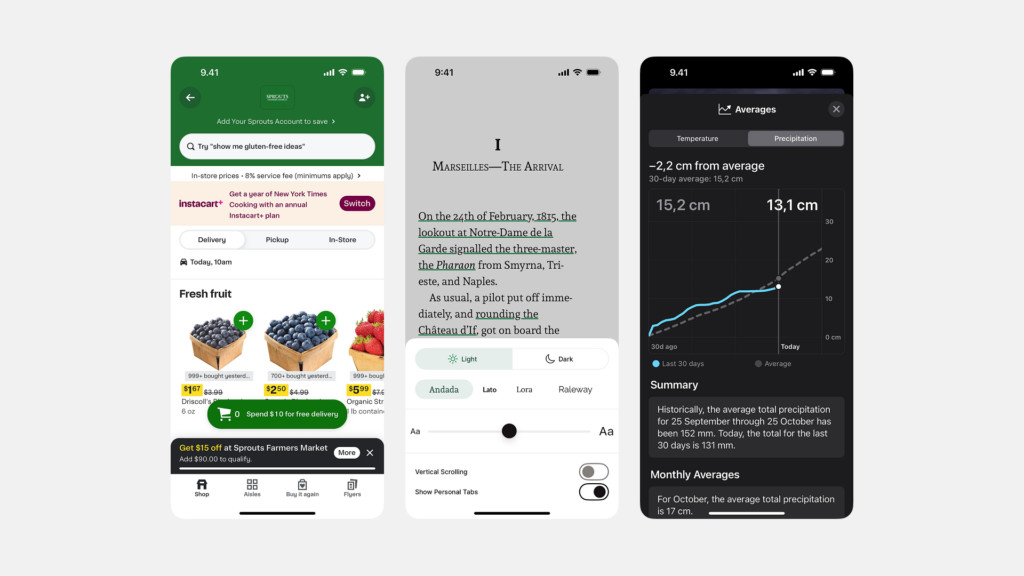
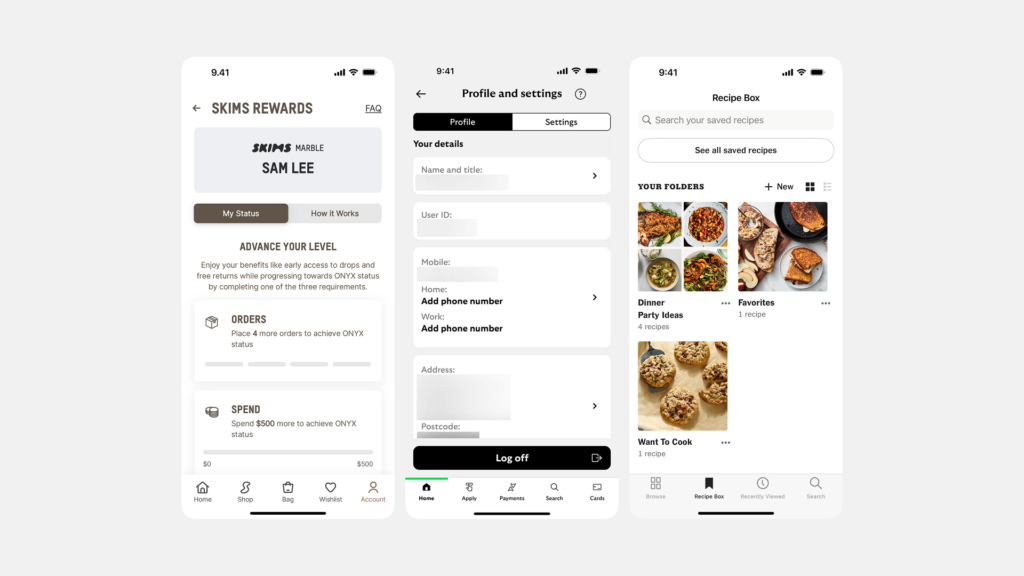
세그먼티드 컨트롤은 주로 서로 연관된 몇 가지(보통 2~5개)의 상호 배타적인(mutually exclusive) 옵션 중에서 하나를 선택하게 하여, 현재 화면의 콘텐츠나 뷰(View)를 변경할 때 사용하는 것이 일반적입니다. 즉, 여러 옵션 중 하나만 활성화될 수 있으며, 선택 시 즉각적으로 관련 내용이 바뀌는 경우에 적합합니다.
주요 사용 사례는 다음과 같습니다.
- 뷰(View) 전환:
- 동일한 데이터 집합을 다른 방식으로 보여주고자 할 때 사용합니다. 사용자가 원하는 정보 제시 방식을 선택할 수 있습니다.
- 예시: 지도 앱에서 ‘지도’ 보기 / ‘목록’ 보기 전환, 차트(그래프)의 ‘일간’ / ‘주간’ / ‘월간’ 데이터 보기 전환, 검색 결과의 ‘정확도순’ / ‘최신순’ 정렬 방식 변경
- 콘텐츠 필터링:
- 현재 화면에 표시되는 콘텐츠 목록을 특정 기준에 따라 필터링하여 보여줄 때 유용합니다.
- 예시: 메일 앱에서 ‘전체’ / ‘안 읽음’ / ‘중요’ 메일 필터링, 쇼핑 앱에서 ‘모든 상품’ / ‘세일 상품’ 필터링, 뉴스피드에서 ‘최신’ / ‘인기’ 게시물 필터링
- 모드(Mode) 변경:
- 앱의 특정 기능이나 섹션 내에서 작동 방식을 변경할 때 사용할 수 있습니다.
- 예시: 단위 변환 앱에서 ‘미터법’ / ‘야드파운드법’ 전환, 계산기 앱에서 ‘일반 계산기’ / ‘공학용 계산기’ 모드 전환 (옵션 수가 적을 경우)
- 간단한 카테고리 선택:
- 매우 제한적이고 명확하게 구분되는 몇 개의 카테고리 중 하나를 선택하여 관련 내용을 표시할 때 사용할 수 있습니다. (탭(Tab)과 유사하게 사용될 수 있으나, 보통 탭은 더 큰 섹션 이동에 사용됩니다.)
세그먼티드 컨트롤을 사용하면 좋은 경우:
- 옵션의 수가 적고 (보통 2~5개) 명확하게 구분될 때
- 선택지가 상호 배타적이어서 하나만 선택 가능할 때
- 선택 즉시 현재 화면의 내용이나 구성이 변경되어야 할 때
- 모든 옵션을 한눈에 보여주고 사용자가 쉽게 비교하며 선택하게 하고 싶을 때
반대로 사용을 피해야 하는 경우:
- 선택해야 할 옵션이 너무 많을 때 (드롭다운 메뉴나 별도 화면 고려)
- 옵션들이 서로 독립적이거나 여러 개를 동시에 선택해야 할 때 (체크박스 고려)
- 완전히 다른 기능이나 섹션으로 이동할 때 (하단 탭 바, 햄버거 메뉴 등 네비게이션 요소 고려)
- 단순 ‘동작’을 실행할 때 (버튼(Button) 사용)
Product Owner 및 UX/UI 관점에서 세그먼티드 컨트롤은 제한된 모바일 화면 공간에서 사용자에게 명확하고 간결한 선택지를 제공하여 정보 탐색이나 뷰 전환을 용이하게 만드는 효과적인 도구입니다. 각 세그먼트의 레이블을 명확하게 작성하고, 현재 선택된 상태를 시각적으로 분명하게 표시하는 것이 중요합니다.
모바일 환경에서 세그멘티드 컨트롤(Segmented Control)은 다음과 같은 상황에서 일반적으로 사용됩니다:
- 뷰 모드 전환: 같은 데이터나 콘텐츠를 다른 형식으로 보여줄 때
- 예: 리스트 보기와 그리드 보기 간 전환
- 예: 캘린더 앱에서 일간/주간/월간 보기 전환
- 필터링 옵션: 데이터를 특정 카테고리나 조건으로 필터링할 때
- 예: 쇼핑 앱에서 ‘전체/인기/신상품’ 필터
- 예: 음악 앱에서 ‘내 플레이리스트/추천/최신’ 필터
- 정렬 기준 선택: 데이터 정렬 방식을 선택할 때
- 예: ‘최신순/인기순/가격순’ 정렬 옵션
- 예: ‘오름차순/내림차순’ 선택
- 시간 범위 선택: 데이터의 시간 범위를 설정할 때
- 예: ‘오늘/이번 주/이번 달/전체’ 선택
- 예: ‘최근 7일/30일/1년’ 선택
- 단순 설정 제어: 두 가지나 소수의 상호 배타적 옵션 중 선택할 때
- 예: 다크 모드/라이트 모드 전환
- 예: 미터법/영국식 단위 전환
- 작은 화면 내 선택지 제공: 제한된 공간에서 선택지를 제공해야 할 때
- 예: 모바일 앱의 상단 툴바에 통합된 선택 옵션
- 예: 팝업이나 모달 창 내부의 옵션 선택
- 즉각적인 콘텐츠 변경: 사용자가 선택하면 즉시 화면 콘텐츠가 변경되어야 할 때
- 예: 뉴스 앱에서 ‘정치/경제/사회/문화’ 섹션 전환
- 예: 주식 앱에서 ‘차트/상세정보/뉴스’ 탭 전환
세그멘티드 컨트롤은 일반적으로 2-5개 정도의 관련성 높은 옵션을 제공할 때 가장 효과적이며, 각 옵션의 레이블이 짧고 명확할 때 사용자 경험이 향상됩니다. 또한 현재 뷰 컨텍스트 내에서 작동하는 선택지를 제공할 때 적합하며, 앱의 전체 네비게이션 구조보다는 현재 화면의 콘텐츠나 동작을 변경하는 데 초점을 맞춥니다.
세그멘티드 컨트롤 (Segmented Control)
- 정의: 수평적으로 배열된 여러 개의 버튼 그룹으로, 사용자가 상호 배타적인 옵션 중 하나를 선택할 수 있게 합니다.
- 시각적 특징: 일반적으로 하나의 직사각형 안에 여러 세그먼트가 나란히 배치되어 있으며, 선택된 세그먼트는 시각적으로 강조됩니다.
- 사용 목적: 단일 뷰 내에서 콘텐츠나 모드를 전환할 때 사용합니다.
- 사용 예시: 지도 앱에서 지도 유형(일반, 위성, 교통) 선택, 텍스트 정렬(왼쪽, 가운데, 오른쪽) 설정 등
- 공간 활용: 일반적으로 작은 공간을 차지하며 뷰 내에 통합됩니다.
- 컨텍스트: 주로 현재 화면 내에서 콘텐츠 변경에 사용됩니다.
탭 (Tab)
- 정의: 화면 상단이나 하단에 위치하여 사용자가 앱의 주요 섹션 간에 이동할 수 있게 하는 네비게이션 요소입니다.
- 시각적 특징: 각 탭은 아이콘과 텍스트 레이블로 구성되며, 활성 탭은 시각적으로 구분됩니다.
- 사용 목적: 앱의 주요 기능 영역이나 섹션 간 탐색에 사용됩니다.
- 사용 예시: SNS 앱의 홈/검색/알림/프로필 탭, 이메일 앱의 받은편지함/보낸편지함/스팸함 탭
- 공간 활용: 일반적으로 화면의 상단 또는 하단 전체를 차지합니다.
- 컨텍스트: 앱의 다른 주요 섹션으로 완전히 전환하는 데 사용됩니다.
주요 차이점
- 기능 범위:
- 세그멘티드 컨트롤: 단일 화면 내에서 관련 콘텐츠나 보기 모드를 전환
- 탭: 앱의 주요 섹션이나 독립적인 기능 영역으로 이동
- 계층 구조:
- 세그멘티드 컨트롤: 낮은 수준의 UI 요소로, 단일 뷰 내에서 작동
- 탭: 높은 수준의 네비게이션 요소로, 앱의 전체 구조를 정의
- 디자인 차이:
- 세그멘티드 컨트롤: 주로 인접한 버튼 그룹으로 표시
- 탭: 일반적으로 더 큰 터치 영역, 아이콘 및 레이블로 구성
- 일반적인 위치:
- 세그멘티드 컨트롤: 콘텐츠 영역 내부나 상단에 배치
- 탭: 화면의 상단(iOS) 또는 하단(Android/iOS)에 고정
- 항목 수:
- 세그멘티드 컨트롤: 일반적으로 2-5개의 옵션으로 제한
- 탭: 플랫폼 가이드라인에 따라 다르지만 보통 3-5개가 일반적
탭은 앱의 주요 네비게이션 구조를 형성하는 반면, 세그멘티드 컨트롤은 단일 화면 내에서 콘텐츠나 기능을 필터링하거나 전환하는 데 사용됩니다. 두 요소 모두 사용자가 쉽게 콘텐츠를 탐색할 수 있도록 도와주지만, 서로 다른 수준의 네비게이션 계층에서 작동합니다.