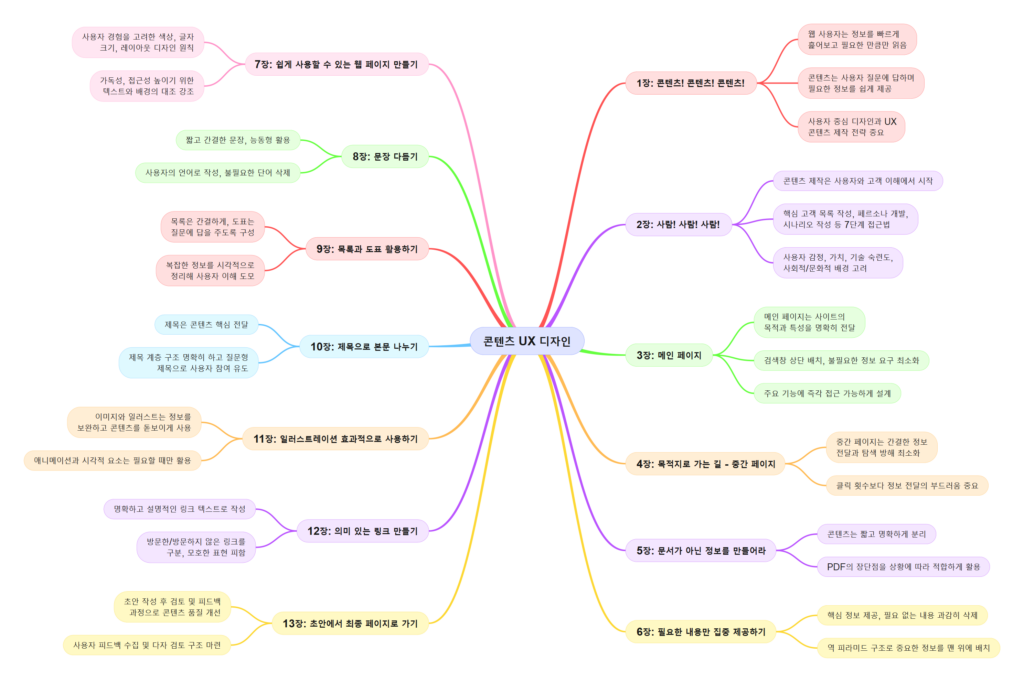
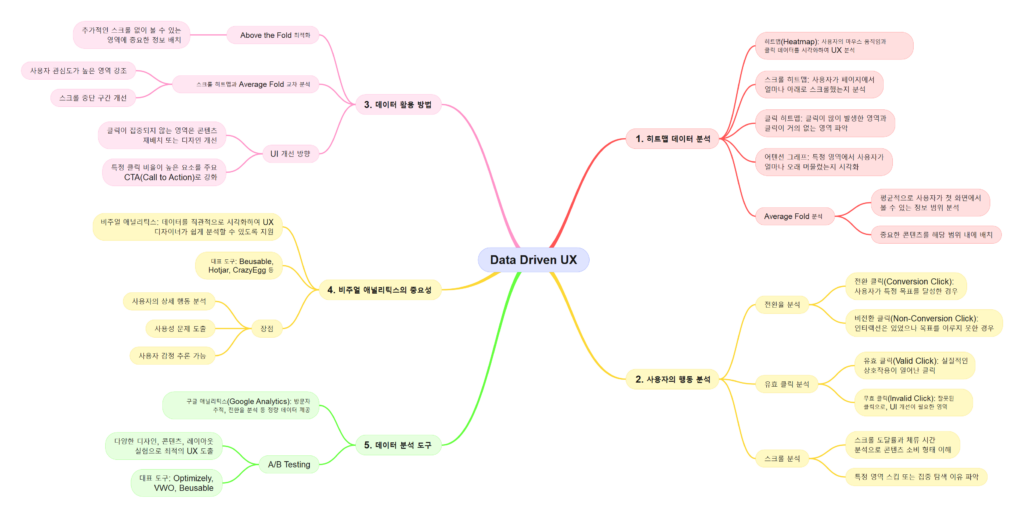
앞서 이커머스 플랫폼 전반에 걸쳐 고려해야 할 UX 핵심 사항들을 살펴보았습니다. 이번에는 사용자 경험을 더욱 향상시키고 플랫폼의 완성도를 높이기 위한 10가지 추가 가이드라인을 제시합니다. 디자인 일관성 유지부터 최신 기술 활용까지, 이 가이드라인들은 사용자 만족도를 극대화하고 브랜드 경험을 강화하는 데 중요한 역할을 합니다.
통합적인 사용자 경험 제공을 위한 추가 가이드라인
1. 검색, 필터, 라우팅 페이지 UI 일관성 유지
검색창, 필터 패널, 리스팅 페이지의 상품 목록 스타일, 카테고리 페이지의 하위 카테고리 노출 방식 등 UI 요소 및 디자인 스타일을 모든 탐색 페이지에서 일관성 있게 유지하여 사용자가 마치 하나의 흐름 속에서 자연스럽게 쇼핑하는 듯한 경험을 제공해야 합니다.
2. 브랜드 아이덴티티 (Brand Identity) 를 검색, 필터, 라우팅 페이지에 반영
웹사이트 전반의 디자인뿐만 아니라 검색창, 필터, 리스팅 페이지, 카테고리 페이지 디자인 곳곳에 브랜드 로고, 브랜드 컬러, 브랜드 폰트, 브랜드 이미지 스타일 등 브랜드 아이덴티티 요소를 반영하여 사용자가 플랫폼을 이용하는 모든 순간에 브랜드 인지도를 높이고 긍정적인 브랜드 이미지를 강화해야 합니다.
3. 접근성 (Accessibility) WCAG (웹 콘텐츠 접근성 지침) 준수
검색, 필터, 리스팅 페이지, 카테고리 페이지는 WCAG (Web Content Accessibility Guidelines) 등 웹 콘텐츠 접근성 지침을 철저히 준수하여 장애를 가진 사용자, 고령 사용자 등 모든 사용자가 웹 콘텐츠를 차별 없이 편리하게 이용할 수 있도록 해야 합니다.
4. 정기적인 사용성 테스트 (Usability Testing) 를 통해 문제점 개선
실제 사용자를 대상으로 검색, 필터, 리스팅 페이지, 카테고리 페이지에 대한 정기적인 사용성 테스트 (Usability Testing) 를 실시하여 사용자들이 탐색 과정에서 겪는 어려움과 문제점을 파악하고, 테스트 결과를 바탕으로 디자인 및 기능을 개선하여 사용자 경험을 지속적으로 향상시켜야 합니다.
5. 사용자 데이터 분석 (User Data Analytics) 기반으로 개선
Google Analytics와 같은 웹 분석 도구를 활용하여 사용자의 검색 데이터, 필터 사용 데이터, 페이지 이동 경로, 체류 시간 등 사용자 행동 데이터를 면밀히 분석하고, 데이터 기반으로 검색, 필터, 라우팅 페이지를 지속적으로 개선하여 사용자 만족도를 높여야 합니다.
6. A/B 테스트 (A/B Testing) 를 통해 디자인 요소 및 기능 최적화
검색창 디자인, 필터 UI, 리스팅 페이지 레이아웃, 카테고리 페이지 구성 등 다양한 디자인 요소 및 핵심 기능들을 A/B 테스트 (A/B Testing) 하여 사용자 반응을 객관적으로 비교 분석하고, 가장 효과적인 디자인 및 기능을 채택하여 사용자 경험을 최적화해야 합니다.
7. 개인화 (Personalization) 기술 적용 (선택 사항)
사용자의 검색 기록, 탐색 패턴, 구매 이력, 관심사 등을 정밀하게 분석하여 검색 결과 개인화, 필터 옵션 개인화, 상품 추천 개인화 등 개인화 (Personalization) 기술을 검색, 필터, 라우팅 페이지에 적용하여 사용자 경험을 맞춤형으로 향상시키고 구매 전환율을 효과적으로 높이는 것을 고려할 수 있습니다.
8. AI (인공지능) 기반 검색 기능 강화 (선택 사항)
자연어 처리 (NLP), 머신러닝 (Machine Learning) 등 AI (인공지능) 기술을 검색 기능에 적용하여 사용자의 검색 의도를 정확하게 파악하고, 검색 정확도 및 검색 효율성을 획기적으로 향상시키며, 사용자 맞춤형 검색 결과를 제공하는 것을 고려할 수 있습니다.
9. 검색 성능 최적화 및 인프라 (Infrastructure) 지속적인 관리
검색 엔진 최적화 (Search Engine Optimization) 및 검색 인덱스 (Search Index) 관리, 검색 서버 성능 관리 등 검색 기능 관련 인프라 (Infrastructure) 를 지속적으로 점검하고 성능을 최적화하여 사용자에게 빠르고 안정적인 검색 서비스를 제공해야 합니다. 검색 속도는 사용자 경험에 직접적인 영향을 미치는 중요한 요소입니다.
10. 검색 품질 평가 및 검색 알고리즘 개선 (Search Algorithm Improvement)
검색 품질 평가 지표 (Search Quality Evaluation Metrics) 를 명확하게 설정하고, 정기적인 검색 품질 평가를 통해 검색 알고리즘 (Search Algorithm) 을 지속적으로 개선하여 검색 정확도 및 사용자 만족도를 꾸준히 향상시켜야 합니다.
핵심 개념 요약: 전반적인 UX 고려 사항은 디자인 일관성, 브랜드 아이덴티티 반영, 접근성 준수, 사용자 테스트 및 데이터 분석 기반 개선, A/B 테스트, 개인화, AI 활용, 검색 성능 최적화 등을 포함합니다.
사례 요약: 성공적인 이커머스 플랫폼들은 제시된 추가 가이드라인들을 적극적으로 활용하여 사용자에게 최상의 쇼핑 경험을 제공하고 있습니다.
마무리: 사용자 중심의 통합적인 UX 디자인을 위해 제시된 모든 가이드라인들을 숙지하고 지속적으로 개선해 나가는 것이 이커머스 플랫폼의 성공을 위한 핵심 전략입니다.
#이커머스 #UX #사용자경험 #디자인일관성 #브랜드아이덴티티 #웹접근성 #사용성테스트 #사용자데이터분석 #AB테스트 #개인화 #인공지능 #검색최적화